
Predict Heart Disease With C# And ML.NET Machine Learning

Twenty years ago, something strange happened to my dad. He was out of breath all the time. Climbing the stairs left him exhausted. Gardening became a struggle. Even simple activities tired him out.
So he went to a specialist for a checkup. The doctor put him on an exercise bike, hooked him up to an EKG machine, and told him to start pedaling.
My dad told me later that he barely got started when the doctor yelled “Stop! stop!” and called an ambulance right away, because he recognized that my father was just days away from having a major heart attack.
The doctor who read the EKG and saved my father’s life instantly recognized the signs of a pending heart attack.
But here’s a question: could we train a machine to do the same?
Wearables are getting smarter all the time. We are very close to having watches that can measure heart activity and alert a doctor if something is wrong. This technology can and will save lives!
So in this article, I am going to build a C# app with ML.NET and NET Core that reads medical data and predicts if a patient has a risk of heart disease. I will show you how we can reproduce the skills of my father’s doctor with just 200 lines of code.
ML.NET is Microsoft’s new machine learning library. It can run linear regression, logistic classification, clustering, deep learning, and many other machine learning algorithms.
The first thing I need for my app is a data file with patients, their medical info, and their heart disease risk assessment. I will use the famous UCI Heart Disease Dataset which has real-life data from 303 patients.
The training data file looks like this:
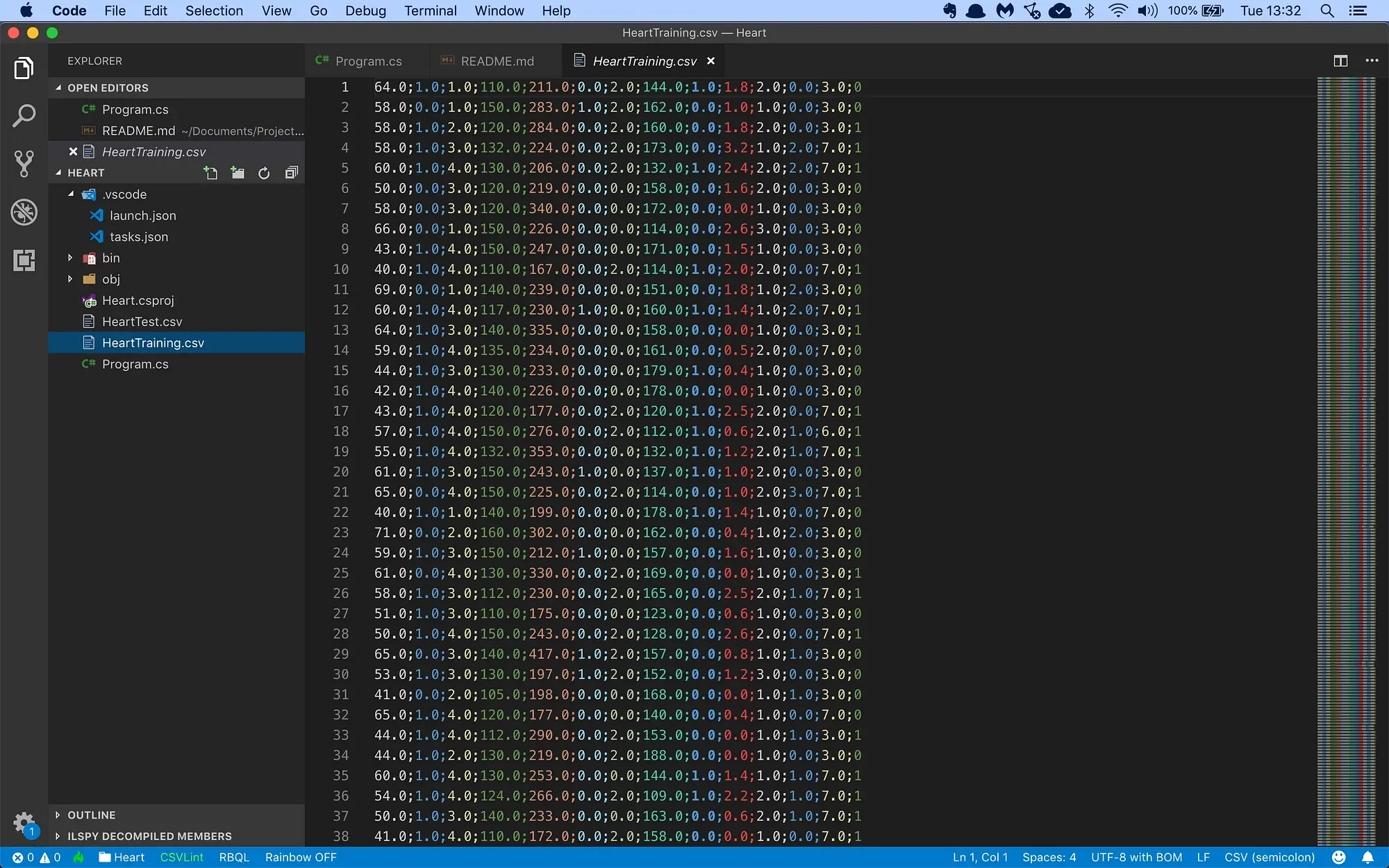
This is a CSV file with 14 columns of information:
- The patient age
- The sex of the patient: 1 = male, 0 = female
- The type of chest pain: 1 = typical angina, 2 = atypical angina , 3 = non-anginal pain, 4 = asymptomatic
- The resting blood pressure in mm Hg on admission to the hospital
- Serum cholesterol in mg/dl
- The fasting blood sugar > 120 mg/dl: 1 = true; 0 = false
- The resting EKG results: 0 = normal, 1 = having ST-T wave abnormality, 2 = showing probable or definite left ventricular hypertrophy by Estes’ criteria
- The maximum heart rate achieved during exercise
- If the exercise induced angina: 1 = yes; 0 = no
- The EKG ST depression induced by exercise relative to rest
- The Slope of the peak exercise EKG ST segment: 1 = up-sloping, 2 = flat, 3 = down-sloping
- The number of major vessels (0–3) colored by fluoroscopy
- Thallium heart scan results: 3 = normal, 6 = fixed defect, 7 = reversible defect
- Diagnosis of heart disease: 0 = less than 50% diameter narrowing, 1 = more than 50% diameter narrowing
The first 13 columns are patient diagnostic information, and the last column is the diagnosis: 0 means a healthy patient, and 1 means an elevated risk of heart disease.
I will build a binary classification machine learning model that reads in all 13 columns of patient information, and then makes a prediction for the heart disease risk.
Let’s get started. Here’s how to set up a new console project in NET Core:
$ dotnet new console -o Heart
$ cd HeartNext, I need to install the ML.NET base package:
$ dotnet add package Microsoft.MLNow I’m ready to add some classes. I’ll need one to hold patient info, and one to hold my model predictions.
I will modify the Program.cs file like this:
/// <summary>
/// The HeartData record holds one single heart data record.
/// </summary>
public class HeartData
{
[LoadColumn(0)] public float Age { get; set; }
[LoadColumn(1)] public float Sex { get; set; }
[LoadColumn(2)] public float Cp { get; set; }
[LoadColumn(3)] public float TrestBps { get; set; }
[LoadColumn(4)] public float Chol { get; set; }
[LoadColumn(5)] public float Fbs { get; set; }
[LoadColumn(6)] public float RestEcg { get; set; }
[LoadColumn(7)] public float Thalac { get; set; }
[LoadColumn(8)] public float Exang { get; set; }
[LoadColumn(9)] public float OldPeak { get; set; }
[LoadColumn(10)] public float Slope { get; set; }
[LoadColumn(11)] public float Ca { get; set; }
[LoadColumn(12)] public float Thal { get; set; }
[LoadColumn(13)] public bool Label { get; set; }
}
/// <summary>
/// The HeartPrediction class contains a single heart data prediction.
/// </summary>
public class HeartPrediction
{
[ColumnName("PredictedLabel")] public bool Prediction;
public float Probability;
public float Score;
}
// The rest of the code goes here...The HeartData class holds one single patient record. Note how each field is adorned with a Column attribute that tell the CSV data loading code which column to import data from.
I’m also declaring a HeartPrediction class which will hold a single heart disease prediction.
Now I’m going to load the training data in memory:
/// <summary>
/// The application class.
/// </summary>
public class Program
{
// filenames for training and test data
private static string trainingDataPath = Path.Combine(Environment.CurrentDirectory, "HeartTraining.csv");
private static string testDataPath = Path.Combine(Environment.CurrentDirectory, "HeartTest.csv");
/// <summary>
/// The main applicaton entry point.
/// </summary>
/// <param name="args">The command line arguments.</param>
public static void Main(string[] args)
{
// set up a machine learning context
var mlContext = new MLContext();
// load training and test data
Console.WriteLine("Loading data...");
var trainingDataView = mlContext.Data.LoadFromTextFile<HeartData>(trainingDataPath, hasHeader: true, separatorChar: ';');
var testDataView = mlContext.Data.LoadFromTextFile<HeartData>(testDataPath, hasHeader: true, separatorChar: ';');
// the rest of the code goes here...
}
}This code uses the method LoadFromTextFile to load the CSV data directly into memory. The class field annotations tell the method how to store the loaded data in the HeartData class.
Now I’m ready to start building the machine learning model:
// set up a training pipeline
// step 1: concatenate all feature columns
var pipeline = mlContext.Transforms.Concatenate(
"Features",
"Age",
"Sex",
"Cp",
"TrestBps",
"Chol",
"Fbs",
"RestEcg",
"Thalac",
"Exang",
"OldPeak",
"Slope",
"Ca",
"Thal")
// step 2: set up a fast tree learner
.Append(mlContext.BinaryClassification.Trainers.FastTree(
labelColumnName: DefaultColumnNames.Label,
featureColumnName: DefaultColumnNames.Features));
// train the model
Console.WriteLine("Training model...");
var trainedModel = pipeline.Fit(trainingDataView);
// the rest of the code goes here...Machine learning models in ML.NET are built with pipelines, which are sequences of data-loading, transformation, and learning components.
My pipeline has the following components:
- Concatenate which combines all input data columns into a single column called Features. This is a required step because ML.NET can only train on a single input column.
- A FastTree classification learner which will train the model to make accurate predictions.
The FastTreeBinaryClassificationTrainer is a very nice training algorithm that uses gradient boosting, a machine learning technique for classification problems.
With the pipeline fully assembled, I can train the model with a call to Fit(…).
I now have a fully- trained model. So now I need to take the test data, predict the diagnosis for each patient, and calculate the accuracy metrics of my model:
// make predictions for the test data set
Console.WriteLine("Evaluating model...");
var predictions = trainedModel.Transform(testDataView);
// compare the predictions with the ground truth
var metrics = mlContext.BinaryClassification.Evaluate(
data: predictions,
label: DefaultColumnNames.Label,
score: DefaultColumnNames.Score);
// report the results
Console.WriteLine($" Accuracy: {metrics.Accuracy:P2}");
Console.WriteLine($" Auc: {metrics.Auc:P2}");
Console.WriteLine($" Auprc: {metrics.Auprc:P2}");
Console.WriteLine($" F1Score: {metrics.F1Score:P2}");
Console.WriteLine($" LogLoss: {metrics.LogLoss:0.##}");
Console.WriteLine($" LogLossReduction: {metrics.LogLossReduction:0.##}");
Console.WriteLine($" PositivePrecision: {metrics.PositivePrecision:0.##}");
Console.WriteLine($" PositiveRecall: {metrics.PositiveRecall:0.##}");
Console.WriteLine($" NegativePrecision: {metrics.NegativePrecision:0.##}");
Console.WriteLine($" NegativeRecall: {metrics.NegativeRecall:0.##}");
Console.WriteLine();
// the rest of the code goes here...This code calls Transform(…) to set up a diagnosis for every patient in the set, and Evaluate(…) to compare these predictions to the ground truth and automatically calculate all evaluation metrics for me:
- Accuracy: this is the number of correct predictions divided by the total number of predictions.
- AUC: a metric that indicates how accurate the model is: 0 = the model is wrong all the time, 0.5 = the model produces random output, 1 = the model is correct all the time. An AUC of 0.8 or higher is considered good.
- AUCPRC: an alternate AUC metric that performs better for heavily imbalanced datasets with many more negative results than positive.
- F1Score: this is a metric that strikes a balance between Precision and Recall. It’s useful for imbalanced datasets with many more negative results than positive.
- LogLoss: this is a metric that expresses the size of the error in the predictions the model is making. A logloss of zero means every prediction is correct, and the loss value rises as the model makes more and more mistakes.
- LogLossReduction: this metric is also called the Reduction in Information Gain (RIG). It expresses the probability that the model’s predictions are better than random chance.
- PositivePrecision: also called ‘Precision’, this is the fraction of positive predictions that are correct. This is a good metric to use when the cost of a false positive prediction is high.
- PositiveRecall: also called ‘Recall’, this is the fraction of positive predictions out of all positive cases. This is a good metric to use when the cost of a false negative is high.
- NegativePrecision: this is the fraction of negative predictions that are correct.
- NegativeRecall: this is the fraction of negative predictions out of all negative cases.
When monitoring heart disease, I definitely want to avoid false negatives because I don’t want to be sending high-risk patients home and telling them everything is okay.
I also want to avoid false positives, but they are a lot better than a false negative because later tests would probably discover that the patient is healthy after all.
The data set has a nicely balanced distribution of positive and negative labels, so there’s no need to use the AUCPRC or F1Score metrics.
So in our case, I’m going to focus on Recall and AUC to evaluate this model.
To wrap up, I’m going to create a new patient record and ask the model to make a prediction:
// set up a prediction engine
Console.WriteLine("Making a prediction for a sample patient...");
var predictionEngine = trainedModel.CreatePredictionEngine<HeartData, HeartPrediction>(mlContext);
// create a sample patient
var heartData = new HeartData()
{
Age = 36.0f,
Sex = 1.0f,
Cp = 4.0f,
TrestBps = 145.0f,
Chol = 210.0f,
Fbs = 0.0f,
RestEcg = 2.0f,
Thalac = 148.0f,
Exang = 1.0f,
OldPeak = 1.9f,
Slope = 2.0f,
Ca = 1.0f,
Thal = 7.0f,
};
// make the prediction
var prediction = predictionEngine.Predict(heartData);
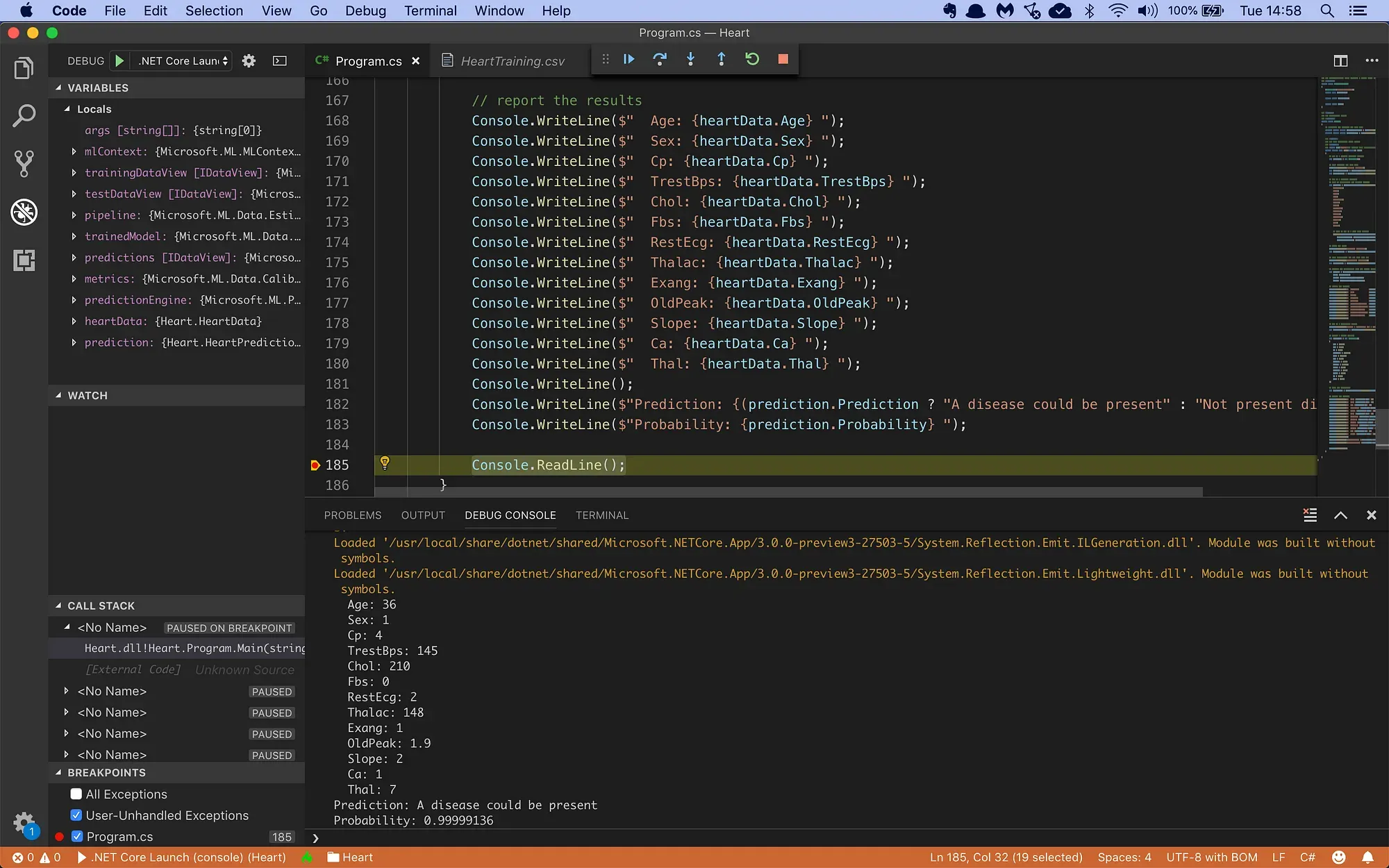
// report the results
Console.WriteLine($" Age: {heartData.Age} ");
Console.WriteLine($" Sex: {heartData.Sex} ");
Console.WriteLine($" Cp: {heartData.Cp} ");
Console.WriteLine($" TrestBps: {heartData.TrestBps} ");
Console.WriteLine($" Chol: {heartData.Chol} ");
Console.WriteLine($" Fbs: {heartData.Fbs} ");
Console.WriteLine($" RestEcg: {heartData.RestEcg} ");
Console.WriteLine($" Thalac: {heartData.Thalac} ");
Console.WriteLine($" Exang: {heartData.Exang} ");
Console.WriteLine($" OldPeak: {heartData.OldPeak} ");
Console.WriteLine($" Slope: {heartData.Slope} ");
Console.WriteLine($" Ca: {heartData.Ca} ");
Console.WriteLine($" Thal: {heartData.Thal} ");
Console.WriteLine();
Console.WriteLine($"Prediction: {(prediction.Prediction ? "A disease could be present" : "Not present disease" )} ");
Console.WriteLine($"Probability: {prediction.Probability} ");I use the CreatePredictionEngine method to set up a prediction engine. The two type arguments are the input data class and the class to hold the prediction. And once my prediction engine is set up, I can simply call Predict(…) to make a single prediction.
I’ve created a patient record for a 36-year old male with asymptomatic chest pain and a bunch of other medical info. What’s the model going to predict?
Here’s the code running in the Visual Studio Code debugger:
… and in a shell window:
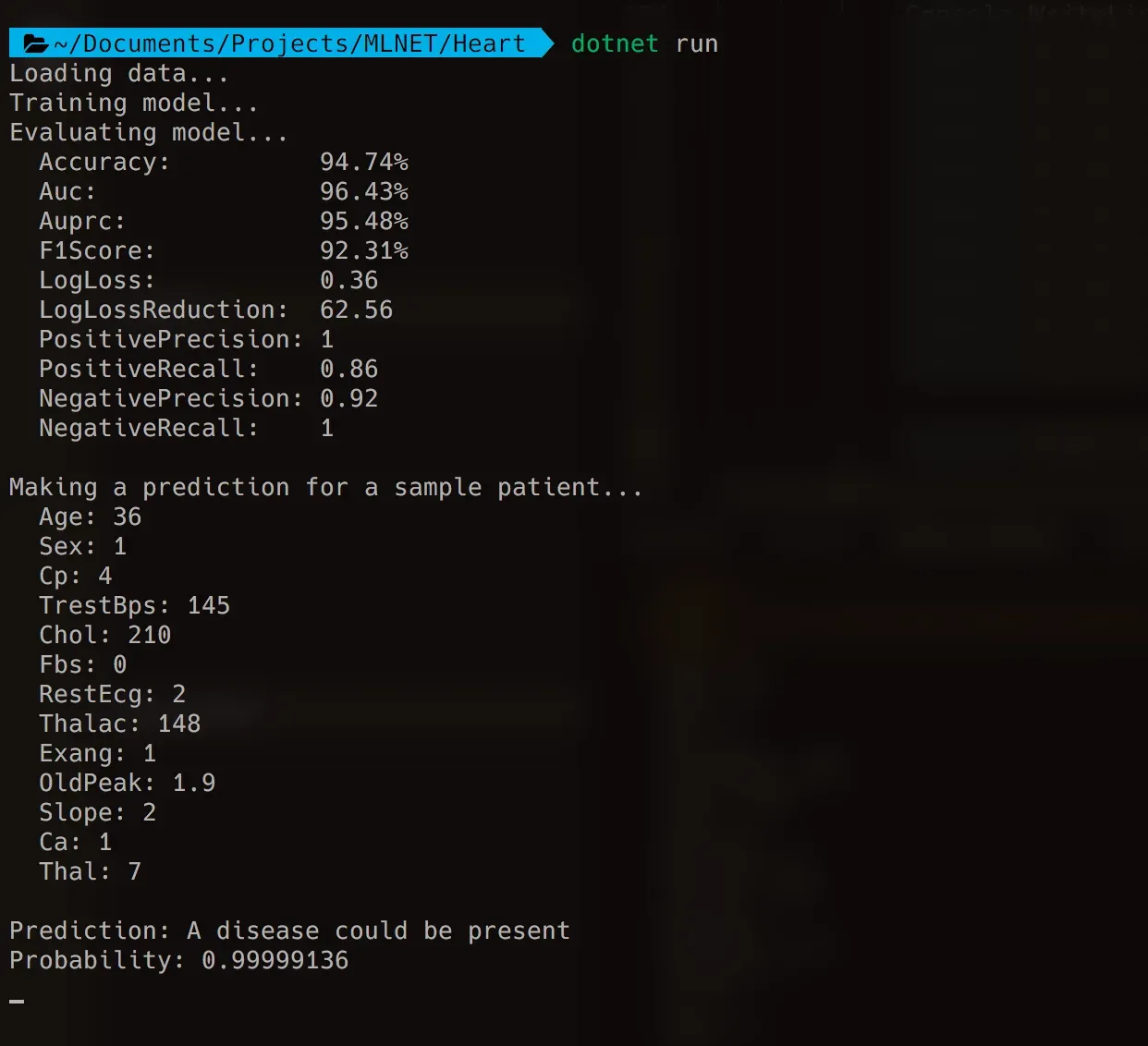
The results nicely illustrate how to evaluate a binary classifier. I get a precision of 1 which is awesome. It means all positive predictions made by the model are correct.
Done deal, right?
Not so fast. The recall is 0.86, which means that out of all positive cases, my model only predicted 86% correct. The remaining 14% are high-risk heart patients who were told that everything is fine and they can go home.
That’s obviously very bad, and it clearly shows how important the recall metric is in cases where we want to avoid false negatives at all costs.
I’m getting an AUC of 96.43% which is a very good result. It means this model has excellent predictive ability.
Finally, my model is 99.99% confident that my 36-year old male patient with asymptomatic chest pain has a high-risk for heart disease.
Looks like we caught that one in time!
C# ML.NET Machine Learning Training
This code is part of my online training course Machine Learning with C# and ML.NET that teaches developers how to build machine learning applications in C# with Microsoft's ML.NET library.

Machine Learning With C# and ML.NET
This course will teach you how to build Machine Learning apps in C# with Microsoft's ML.NET library.
I made this training course after finishing a Machine Learning training course by Google. I really struggled with the complicated technical explanations from the trainer, and I wondered if I could do a better job explaining Machine Learning to my students.
Having been a C# developer for most of my career, I also wondered if it were possible to build advanced Machine Learning apps in C# instead of Python. I had built an Enterprise C# app with a Python AI module earlier in my career, and I was always dissatisfied with the brittleness of the glue-code holding the two languages together. Being able to do everything in C# would take that problem off the table.
Then Microsoft launched their ML.NET Machine Learning library, and conditions were suddenly ideal for me to start developing my own C# Machine Learning training. And the rest is history.
Anyway, check out the training if you like. It will get you up to speed on the ML.NET library and you'll learn the basics of regression, classification, clustering, gradient descent, logistic regression, decision trees, and much more.